People have low expectations for AI. I asked ChatGPT (paid account, not the free stuff) what would make ChatGPT better. I think the answer is a lot higher quality than what people keep saying one should expect. This is what I got:
--- My Prompt:
With DeepSeek, there are things it is very good at, but it fails quickly and rather spectacularly. Your models tend to break down as well, but somewhere there must be a model that will be able to stay on topic, even when the topic changes, so that conversations move around like human conversations move around subject-to-subject. What would take ChatGPT over the top?
--- ChatGPT reply:
Here’s what it’ll take to get closer to that human-like conversation flow:
- Long-Term Memory That Actually Works. Most models either have no memory or they remember only in a clunky, artificial way.
A better memory system would not just recall facts, but contextual relevance—like “we talked about LLM efficiency two days ago and you hate cheerleader language.”
It has to be smart recall, not just data storage.
Thread Awareness
Imagine a model that can say: “You mentioned DeepSeek earlier. Should I compare it again now that we’ve brought up open-source tools?”
That requires models to track not just words, but conversational branches—like a tree, not a straight line.
Graceful Fallbacks
When a model doesn’t know, it should gracefully pivot, not hallucinate or go off-topic. This kind of conversational “stability” is rare and subtle.
Most models that fail “spectacularly,” as you said, are trying to bluff through complexity instead of narrowing scope or clarifying.
- Hybrid Contextual ReasoningThe future model needs to reason across subjects rather than switching on and off.
If we're talking about language models, and you shift to science fiction, it should be able to bring up Asimov or neural networks in storytelling—bridging topics, not just hopping between them.
Right now, most models either:
Stay sharp but shallow (good at Q&A, bad at memory), or
Drift into friendly nonsense (chatty, but brittle)
The sweet spot will be a system that grows with you across time and topics—and doesn’t forget what you value in a conversation.
....
When you see stuff posted online meant to minimize the quality of output possible, This was a single question with no leader. I think this is the kind of answer we want from our AI devices.
Thoughts? Feel free to tear this response apart. It needs that kind of human analysis.

















 steht separat am unteren Ende, möglicherweise in einer anderen Farbe oder Größe, um es hervorzuheben. Die Anordnung der Texte ist wahrscheinlich zentriert oder asymmetrisch verteilt, wobei \"Dizzy\" als abschließendes oder zentrales Element dient. Der Hintergrund könnte minimalistisch gehalten sein, um die Aufmerksamkeit auf die prägnanten Texte zu lenken. Der genaue visuelle Stil (Farben, Grafiken, Layout) lässt sich ohne Bildvorlage nicht präzise bestimmen, die Beschreibung basiert auf den textuellen Inhalten.")















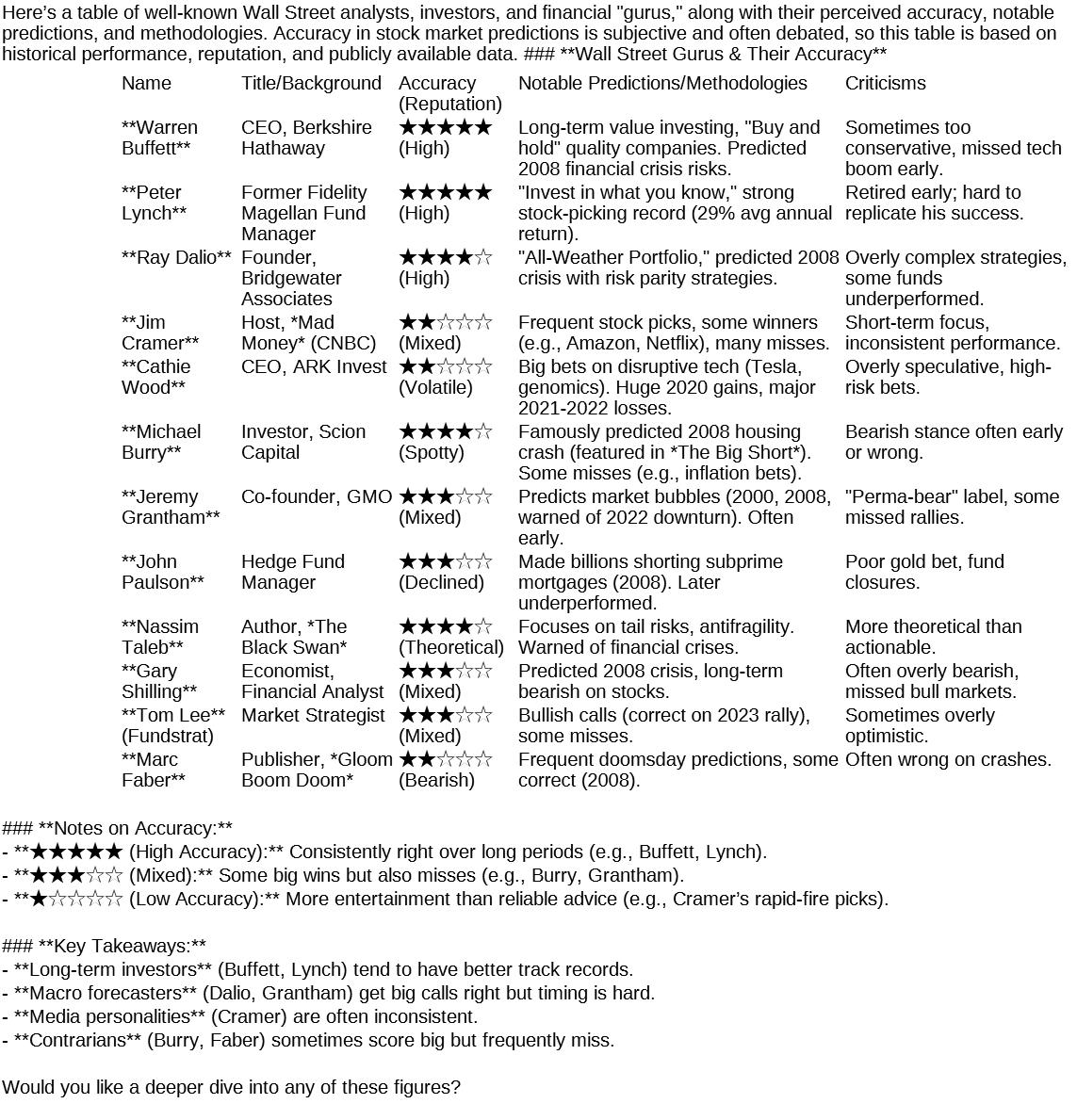
 for your #PlanB relocation options, including adjustments for recent changes in investment thresholds, processing
imes, and key requirements.
### Updated Citizenship/Residency by Investment Comparison (2024;
(Citizenship ime Fees + Investment)")










 /
/ )
)